- 17 jan. 2025
La régression logistique, présentation et concepts mathématiques
- Agar Blohorn
- Algorithmes
- 0 comments
Le machine learning est basé sur la construction de modèles mathématiques et algorithmiques qui une fois implémentés permettent l’apprentissage des machines. Nous avons vu dans le précédent article un modèle d’apprentissage supervisé linéaire appelé régression linéaire simple ou multiple suivant le nombre de variables explicatives. C’est un algorithme visant à prédire une variable cible quantitative à partir de variables connues. Mais qu’en est-il lorsque la variable à prédire est qualitative ? Comment modéliser des variables comportant par exemple deux catégories « malade » et « non malade » ? Nous allons voir ici un nouveau modèle d’apprentissage supervisé, nommé la classification. La classification est un ensemble de méthodes qui permet à partir de données connues, de classer chaque individu dans plusieurs catégories ou classes. Ici, en l’occurrence nous allons voir une méthode de classification nommée la régression logistique binaire.
Avant de nous lancer dans l’explication de ce modèle, voici un schéma récapitulatif simplifié des quelques notions de ML vues jusqu’ici :
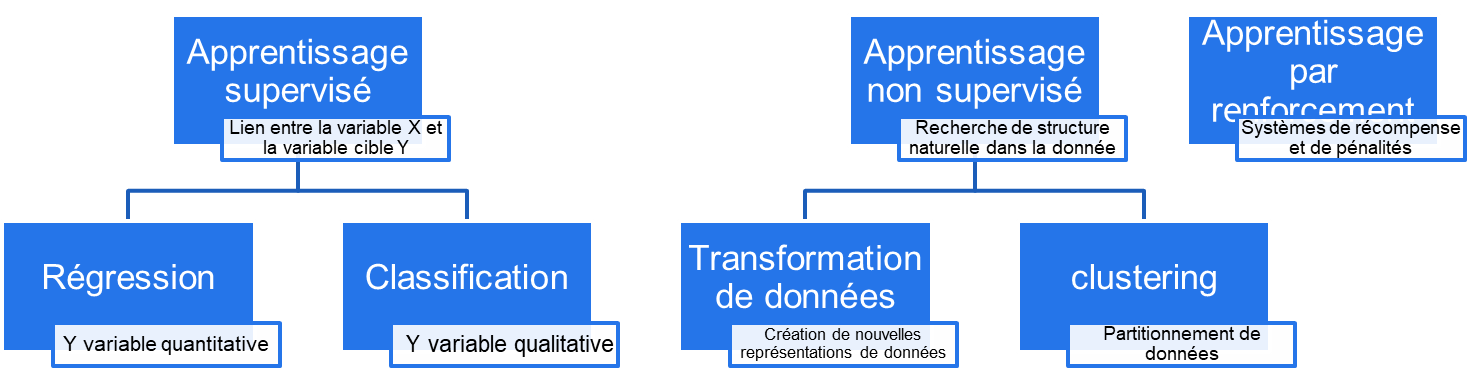
Note : Il ne faut pas confondre la technique d’apprentissage nommée « classification » qui est tirée du modèle d’apprentissage supervisé avec la découverte de classes qui étaient jusque-là inconnues et qui sont nommées « » en anglais, ou « clusterisation » en français, qui elles ne sont pas supervisées par une définition de classes ou catégories a priori.
La régression logistique binaire
La régression linéaire et la régression logistique sont toutes les deux des modèles linéaires visant à caractériser les relations entre variables dépendantes et une ou plusieurs variables indépendantes. La différence entre les deux modèles réside dans la nature quantitative ou qualitative de la variable cible à prédire. Lorsque la variable quantitative tente de répondre à la question « combien ? », la variable qualitative permet de répondre à la question « quelle sorte ? »
L’intérêt de la régression logistique est de répondre à des questions telles que : Est-ce qu’une banque doit accorder un prêt à l’un de ses clients ? ou Est-ce qu’un patient est malade ou non malade ? Où doit-on déclencher une alerte à la pollution atmosphérique ? Ce modèle permet de mesurer la liaison entre la survenue d’un événement (variable cible 𝑌 ) et les facteurs susceptibles de l’influencer (variables explicatives 𝑋). Le choix des variables 𝑋, demande une connaissance a posteriori du phénomène (maladie, conditions de prêt, influence extérieure sur la pollution…) .
L’objectif est de chercher une fonction coût ou classifieur, pour un modèle de classification afin de modéliser 𝑌 ∈{0,1} à l’aide d’une combinaison linéaire des variables explicatives.
Cette combinaison linéaire de variables explicatives appelée fonction score possède la même forme que celle de la régression linéaire :
𝑌= 𝑆(𝑋) avec
𝑆(𝑋)=𝑎1𝑥1+⋯+𝑎𝑝𝑥𝑝, une fonction linéaire
On ne peut pas utiliser le modèle de la régression linéaire dans le cas d’une variable cible qualitative car elle n’admet pas de valeur numérique naturelle, on classe les deux catégories ou les attributs par deux valeurs [0 ou 1] ou [positif ou négatif] . L’idée est donc de rendre le modèle probabiliste, c’est-à-dire qu’au lieu de prédire directement les valeurs de 𝑌, on veut prédire la probabilité d’un individu d’appartenir au groupe 1 ou 0 ou d’être positif ou négatif.
Ici nous traitons de la régression logistique binaire avec deux classes, on l’appelle régression logistique dichotomique, si le nombre de classes est supérieur à deux alors on parle de régression logistique polytomique. Regardons dans le prochain paragraphe ce que nous montre le nuage de points des observations.
Représentation graphique
La figure 1 ci-dessous illustre la forme idéale d’un cas d’utilisation de la régression logistique d’un nuage de points lorsque nous traçons les observations (𝑋𝑖,𝑌𝑖),𝑖=1,…,𝑝.
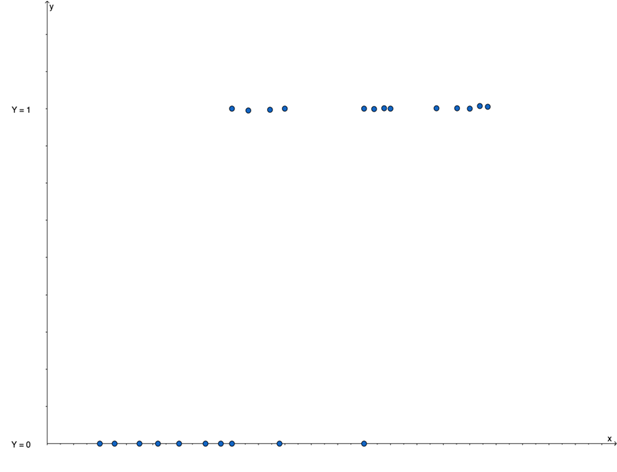
Figure 1
Sous cette forme, il est difficile de voir le lien entre la variable 𝑋 et la variable 𝑌 et d’arriver à trouver une fonction prédictive satisfaisante.
La variable cible est bien qualitative binaire et n’admet pas d’échelle de mesure naturelle, d’où la nécessité de modéliser la probabilité d’un individu d’être dans la catégorie 1,
𝑃(𝑌 =1|𝑋 ) ou dans la catégorie 0, 𝑃(𝑌 =0|𝑋 )=1−𝑃(𝑌 =1|𝑋 ).
On regroupe les données récoltées pendant la phase d’apprentissage en catégories et on calcule le pourcentage de personnes dans chacune de ces catégories. En effet, on utilise au préalable ce qu’on appelle « l’odds ratio » qui exprime le degré de dépendance entre des variables.
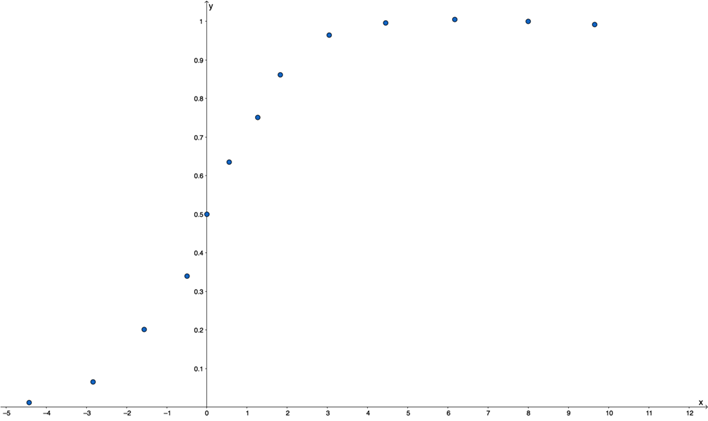
Figure 2
On s’aperçoit dans la figure 2 ci-dessus que l’on a une relation sigmoïdale, en forme de S entre la variable explicative et la variable cible. On en déduit qu’il faudra utiliser une fonction de la forme sigmoïdale pour modéliser les probabilités conditionnelles.
Modélisation
Modèle de la régression logistique
Voyons de plus près la manière dont est construit le modèle de la régression logistique.
On veut modéliser, 𝑃(𝑌 =1 𝑜𝑢 0|𝑋 ) par une combinaison linéaire des variables explicatives or, une probabilité est comprise entre 0 et 1 et cette fonction n’est pas linéaire. C’est pour cela que le modèle de régression logistique se base sur une transformation logit de 𝑃(𝑌 =1 𝑜𝑢 0|𝑋 ) comme une combinaison linéaire de variables explicatives.
On a par exemple:
X une variable quantitative
Y = 0 : absence, décès...
Y = 1 : présence, survie…
Ce qui nous amène à cette expression :
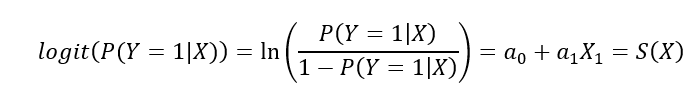
Avec 𝑃(𝑌=1|𝑋)1/𝑃(𝑌=1|𝑋) la quantité exprimant ce qu’on appelle un odd, c’est-à-dire un rapport de chances ou un rapport des côtes. Par exemple, si un individu présente un odd de 4, alors il a 4 fois plus de chances d’être positif ou d’être dans la première catégorie ou négatif ou d’être dans la deuxième catégorie.
Cette formulation, peut être réécrite de cette manière après quelques manipulations mathématiques :
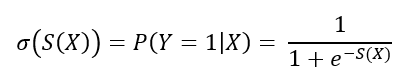
𝜎(𝑆(𝑋)) est la fonction logistique (cf figure 3) qui est la fonction réciproque de la fonction logit (cf figure 4).
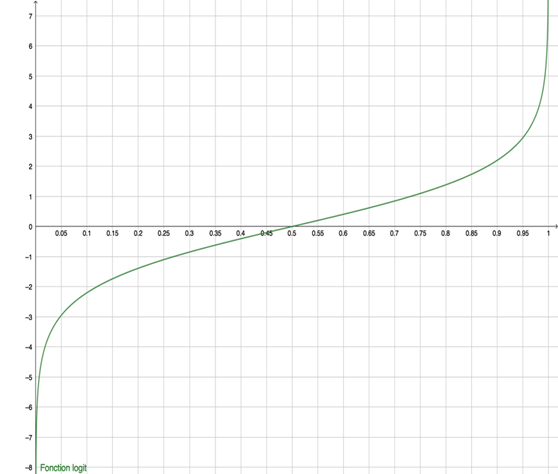
Figure 3 : fonction logit
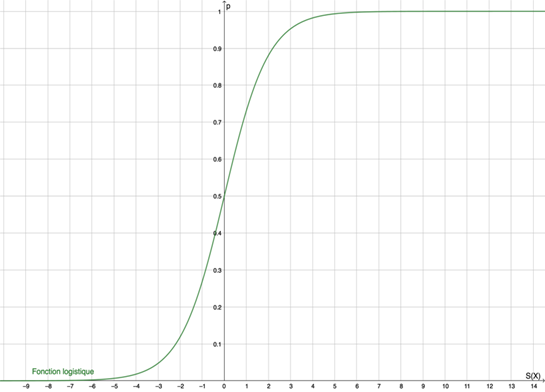
Figure 4 : fonction logistique
La fonction logistique est donc le bon candidat pour la modélisation de la régression logistique, en effet elle prend ses valeurs entre 0 et 1 et elle présente une courbe en forme de S.
Plus la valeur de 𝑋 augmente, et plus on se rapproche de 1/1 car l’exponentielle à la puissance d’un nombre négatif infiniment grand tend vers zéro. Contrairement, plus la valeur de 𝑋 diminue sous 0, plus l’expression 1+𝑒−𝑆(𝑋) grandit, ce qui réduit le quotient.
L’interprétation de la régression logistique est facile, si la valeur de sortie est proche de 0, la probabilité que l’événement survienne est faible, alors que si la valeur de sortie est proche de 1, la probabilité est élevée.
Estimation des coefficients de la droite par la méthode de la maximisation de la vraisemblance
Le vecteur des coefficients (𝑎1,…,𝑎𝑝) de la fonction score S(X) est estimé par maximisation de la vraisemblance. La méthode de la maximisation de la vraisemblance consiste à trouver les coefficients (𝑎1,…,𝑎𝑝) de la régression logistique qui rend maximum la probabilité d’observer cet échantillon, c’est-à-dire la probabilité de succès.
Afin de définir la vraisemblance, on commence par remarquer que le modèle de la régression logistique est basé sur le modèle binomial car 𝑌 est binaire.
On modélise donc la probabilité 𝑃(𝑌|𝑋) avec le modèle binomial suivant :
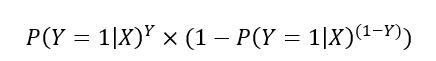
On peut comprendre cette expression de la manière suivante :
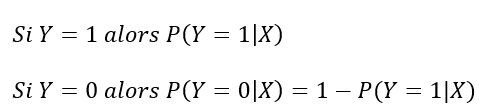
La vraisemblance s’écrit comme le produit du modèle binomial et on prend le logarithme de la vraisemblance pour éliminer les puissances ce qui nous donne :
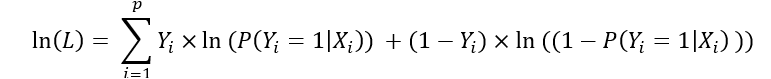
Enfin le maximum de vraisemblance s’obtient en dérivant cette dernière, on obtient le gradient en 𝑎⃗ = (𝑎1,…,𝑎𝑝) qui vaut :
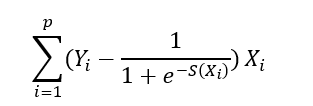
Contrairement à la régression linéaire, il n’existe pas de formules explicites des paramètres, il faut pour cela avoir recours à des méthodes numériques d’optimisation itératives telles que les algorithmes de descente et plus particulièrement l’algorithme de Newton-Raphson.
Conclusion
La régression logistique est un problème de classification binaire. Utiliser la fonction coût logistique revient à maximiser la vraisemblance du modèle dans lequel la probabilité d’appartenir à la classe 1 ou la classe positive est la transformée logit d’une combinaison linéaire des variables explicatives. Elle demande toutefois d’avoir recours à des algorithmes d’optimisation pour apprendre le modèle et estimer les paramètres de la fonction score.
L’inconvénient est que la phase d’apprentissage de notre modèle peut être longue car l’opération numérique d’optimisation des coefficients (𝑎1,…,𝑎𝑝) est complexe.
On peut étendre ce modèle à des variables polytomiques (Y pouvant appartenir à plus de deux classes) en enchainant plusieurs régressions logistiques.
Nous verrons dans un prochain article, un modèle d’apprentissage non supervisé, l’algorithme des k-moyennes.